

研究指责LM Arena帮助顶级AI实验室玩弄其基准
人工智能实验室 Cohere、斯坦福大学、麻省理工学院和 Ai2 联合发表的一篇新论文指责 LM Arena(流行众包人工智能基准 Chatbot Arena 背后的组织)帮助一组精选的人工智能公司以牺牲竞争对手为代价获得更好的排行榜分数。
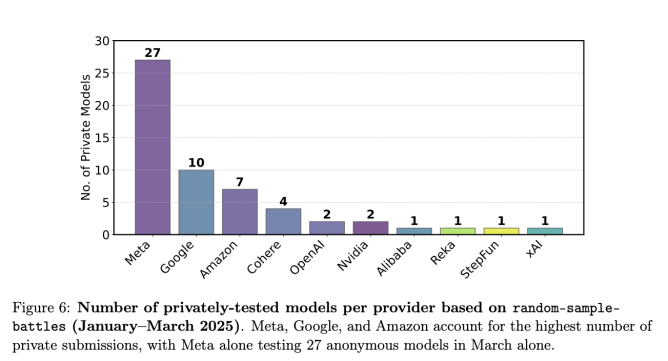
据作者称,LM Arena 允许一些行业领先的人工智能公司(例如 Meta、OpenAI、谷歌和亚马逊)私下测试多种人工智能模型变体,并且不公布表现最差的模型的得分。作者表示,这使得这些公司更容易在该平台的排行榜上名列前茅,尽管并非每家公司都有这样的机会。
Cohere 人工智能研究副总裁兼该研究报告合著者萨拉·胡克 (Sara Hooker) 在接受 TechCrunch 采访时表示:“只有少数几家公司被告知可以进行这种私人测试,而且有些公司获得的私人测试数量比其他公司多得多。这就是游戏化。”
Chatbot Arena 于 2023 年由加州大学伯克利分校创建,最初是一个学术研究项目,如今已成为人工智能公司的标杆。它的工作原理是将两个不同的人工智能模型的答案并排进行“对战”,并要求用户选择最佳答案。在竞技场中,经常可以看到未发布的模型以假名参赛。
随着时间的推移,投票会影响模型的得分,从而影响其在 Chatbot Arena 排行榜上的排名。虽然许多商业参与者参与 Chatbot Arena,但 LM Arena 长期以来始终坚持其基准的公正性和公平性。
然而,这并不是论文作者所说的他们发现的内容。
作者称,在科技巨头 Meta 发布 Llama 4 之前的 1 月至 3 月期间,一家名为 Meta 的人工智能公司在 Chatbot Arena 上私下测试了 27 种模型变体。在发布时,Meta 只公开透露了一个模型的得分——而这个模型恰好在 Chatbot Arena 排行榜上名列前茅。
研究指责LM Arena帮助顶级AI实验室玩弄其基准
这项研究的图表。(图片来源:Singh 等人)
LM Arena 联合创始人兼加州大学伯克利分校教授 Ion Stoica 在给 TechCrunch 的一封电子邮件中表示,这项研究充满了“不准确之处”和“值得怀疑的分析”。
LM Arena 在提供给 TechCrunch 的一份声明中表示:“我们致力于公平、以社区为主导的评估,并邀请所有模型提供商提交更多模型进行测试,以提升其在人类偏好方面的表现。如果一个模型提供商选择比其他模型提供商提交更多的测试,这并不意味着第二个模型提供商受到了不公平的对待。”
据称受青睐的实验室
论文作者在得知一些人工智能公司可能获得Chatbot Arena的优先使用权后,于2024年11月开始进行研究。他们在五个月的时间里总共测量了超过280万场Chatbot Arena的对战。
作者表示,他们发现的证据表明,LM Arena 允许某些 AI 公司(包括 Meta、OpenAI 和 Google)通过让其模型出现在更多模型“战斗”中,从 Chatbot Arena 收集更多数据。作者声称,这种提高的采样率给这些公司带来了不公平的优势。
使用来自 LM Arena 的额外数据可以将模型在 Arena Hard(LM Arena 维护的另一个基准)上的性能提升 112%。然而,LM Arena 在 X 上的一篇帖子中表示 ,Arena Hard 的性能与 Chatbot Arena 的性能并不直接相关。
胡克表示,目前尚不清楚某些人工智能公司如何获得优先访问权,但无论如何,LM Arena 都有责任提高其透明度。
LM Arena 在X 上的一篇文章中表示,论文中的一些说法并不反映现实。该组织指出,本周早些时候发布的一篇 博客文章指出,来自非主流实验室的模型在 Chatbot Arena 比赛中出现的次数比研究结果显示的要多。
这项研究的一个重要局限性在于,它依赖于“自我识别”来确定哪些AI模型在Chatbot Arena上进行私下测试。作者多次提示AI模型它们来自哪个公司,并依靠模型的回答对它们进行分类——这种方法并非万无一失。
然而,胡克表示,当作者联系 LM Arena 分享他们的初步发现时,该组织并没有提出异议。
TechCrunch 联系了 Meta、谷歌、OpenAI 和亚马逊(这些公司均在研究中被提及)征求意见,但均未立即回复。
LM Arena陷入困境
在论文中,作者呼吁 LM Arena 实施一系列变革,旨在使 Chatbot Arena 更加“公平”。例如,作者表示,LM Arena 可以对 AI 实验室可以进行的私人测试数量设定清晰透明的限制,并公开披露这些测试的分数。
LM Arena 在X 上的一篇帖子中 驳斥了这些建议,声称其自 2024 年 3 月以来 就已发布了预发布测试的信息 。该基准测试机构还表示,“显示尚未公开的预发布模型的分数毫无意义”,因为 AI 社区无法自行测试这些模型。
研究人员还表示,LM Arena 可以调整 Chatbot Arena 的采样率,以确保竞技场中的所有模型都参与相同数量的战斗。LM Arena 已公开采纳了这一建议,并表示将创建新的采样算法。
这篇论文发表于几周前,Meta 被发现在其上述 Llama 4 模型发布前后,在 Chatbot Arena 上进行游戏基准测试。Meta 对其中一款 Llama 4 模型进行了“对话性”优化,这帮助它在 Chatbot Arena 的排行榜上取得了令人印象深刻的成绩。但该公司从未发布过优化后的模型——而原始版本 最终在 Chatbot Arena 上的表现要差得多。
当时,LM Arena 表示 Meta 在基准测试方法上应该更加透明。
本月初,LM Arena 宣布成立一家公司,计划从投资者那里筹集资金。这项研究加强了对私人基准测试机构的审查——以及它们是否值得信赖,能够评估人工智能模型,而不会受到企业影响。
2025年4月30日晚上9:35(太平洋时间)更新:本文之前的版本包含一位谷歌DeepMind工程师的评论,他指出Cohere的研究部分内容不准确。这位研究人员并没有否认谷歌在1月至3月期间向LM Arena发送了10个模型进行预发布测试(正如Cohere所声称的那样),只是指出该公司负责Gemma开发的开源团队只发送了一个模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...