
人工智能硬件初创公司Cerebras创建了一种新的人工智能推理解决方案,可能与Nvidia为企业提供的 GPU产品相媲美。

Cerebras 与 Nvidia:新的推理工具有望实现更高的性能
Cerebras Inference 工具基于该公司的 Wafer-Scale Engine,并有望提供惊人的性能。据消息人士透露,该工具已实现 Llama 3.1 8B 每秒 1,800 个令牌的速度,Llama 3.1 70B 每秒 450 个令牌的速度。Cerebras 声称,这些速度不仅比 Nvidia 的 GPU 生成这些系统所需的通常超大规模云产品更快,而且更具成本效益。
正如 Gartner 分析师 Arun Chandrasekaran 所说,这是进入生成式 AI 市场的重大转变。虽然这个市场之前的重点是训练,但目前正在转向推理的成本和速度。这种转变是由于企业环境中 AI 使用案例的增长,并为 Cerebras 等 AI 产品和服务供应商提供了基于性能展开竞争的绝佳机会。
正如 Artificial Analysis 联合创始人兼首席执行官 Micah Hill-Smith 所说,Cerebras 在 AI 推理基准测试中表现出色。该公司的测量结果显示,在 Llama 3.1 8B 上每秒输出超过 1,800 个 token,在 Llama 3.1 70B 上每秒输出超过 446 个 token。这样,他们在两个基准测试中都创下了新纪录。
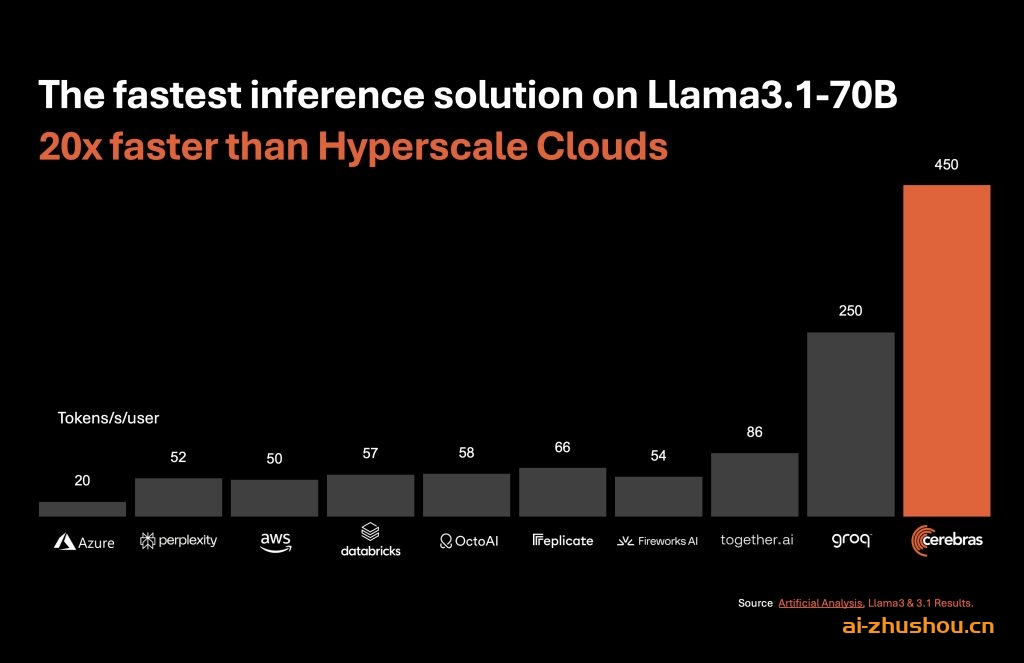
Cerebras 推出了速度提高 20 倍而成本仅为 GPU 的一小部分的 AI 推理工具
Cerebras 推出了速度提高 20 倍而成本仅为 GPU 的一小部分的 AI 推理工具。
然而,尽管具有潜在的性能优势,Cerebras 在企业市场仍面临重大挑战。Nvidia 的软件和硬件堆栈在行业中占据主导地位,并被企业广泛采用。Futurum Group 分析师 David Nicholson 指出,虽然 Cerebras 的晶圆级系统能够以比 Nvidia 更低的成本提供高性能,但关键问题是企业是否愿意调整其工程流程以适应 Cerebras 的系统。
在 Nvidia 和 Cerebras 等替代方案之间做出选择取决于几个因素,包括运营规模和可用资本。较小的公司可能会选择 Nvidia,因为它提供已经成熟的解决方案。同时,拥有更多资本的大型企业可能会选择后者来提高效率并节省成本。
随着人工智能硬件市场的不断发展,Cerebras 还将面临来自专业云提供商、微软、AWS 和谷歌等超大规模提供商以及 Groq 等专用推理提供商的竞争。性能、成本和易实施性之间的平衡可能会影响企业采用新推理技术的决策。
每秒能够超过 1,000 个 token 的高速 AI 推理的出现相当于宽带互联网的发展,这可能为 AI 应用开辟新的领域。Cerebras 的 16 位精度和更快的推理能力可能有助于创建未来的 AI 应用程序,其中整个 AI 代理必须快速、重复和实时地运行。
随着人工智能领域的发展,人工智能推理硬件市场也在不断扩大。该领域约占整个人工智能硬件市场的 40%,正成为更广泛的人工智能硬件行业中越来越有利可图的目标。鉴于更知名的公司占据了这一领域的大部分份额,许多新进入者应该仔细考虑这一竞争格局的重要方面,考虑到竞争性质以及驾驭企业领域所需的大量资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...