

谷歌 Gemini 1.5 Pro 取代 GPT-4o
谷歌的实验性Gemini 1.5 Pro模型在生成式 AI 基准测试中已经超越了 OpenAI 的GPT-4o 。
在过去的一年里,OpenAI 的 GPT-4o 和 Anthropic 的Claude-3占据了主导地位。然而,最新版本的 Gemini 1.5 Pro 似乎已经占据了主导地位。
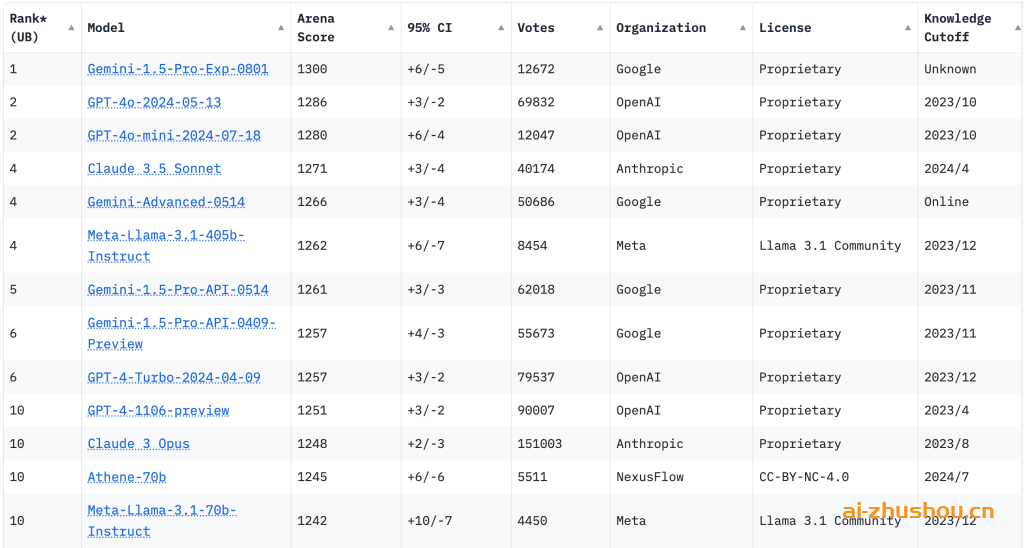
人工智能社区最受认可的基准之一是 LMSYS Chatbot Arena,它评估各种任务的模型并分配总体能力分数。在这个排行榜上,GPT-4o 获得了 1,286 分,而 Claude-3 获得了值得称赞的 1,271 分。Gemini 1.5 Pro 的上一版本得分为 1,261 分。
谷歌 Gemini 1.5 Pro 取代 GPT-4o
Gemini 1.5 Pro 的实验版本(指定为 Gemini 1.5 Pro 0801)以 1,300 分的惊人成绩超越了其最接近的竞争对手。这一显着的进步表明,Google 的最新型号可能拥有比其竞争对手更强大的整体功能。
值得注意的是,虽然基准测试为人工智能模型的性能提供了有价值的见解,但它们可能并不总是准确地代表其在实际应用中的全部能力或局限性。
尽管 Gemini 1.5 Pro 目前已经上市,但它被标记为早期版本或处于测试阶段,这表明谷歌仍可能出于安全或协调原因对该模型进行调整甚至撤回。
这一进展标志着科技巨头之间争夺人工智能霸主地位的持续竞争中的一个重要里程碑。谷歌能够在基准测试中超越 OpenAI 和 Anthropic,这表明该领域的创新步伐很快,竞争激烈,推动了这些进步。
随着人工智能领域的不断发展,OpenAI 和 Anthropic 如何应对来自谷歌的挑战将会很有趣。他们能否重新夺回排行榜榜首的位置,或者谷歌是否为生成式人工智能的性能建立了新的标准?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...